
О пользе регулярных ревизий запросов в кэше и результативности покрывающих индексов.
На одном из серверов в плане запросов (процедура) были выявлены дорогие операции
Один запрос:
RID Lookup, две по одной таблице 887 Mb data
Второй запрос:
Key Lookup, одна, по таблице 14.3 Gb data
Особых замечаний по производительности не высказывалось, в то же время было решено создать покрывающие индексы.
Первый запрос, было:
RID Lookup
стоимость 35,0078 (43%)
RID Lookup
Стоимость 31,9308 (39%)
Стало:
Index Scan
15,686 (41%)
Index Scan
15,686 (41%)
Скан по индексу не самая благообразная операция (по логике идет большая выборка), но стоимость снизилась в 2 раза
Суммарная стоимость первого запроса была 81,048 стала 38,4374
Второй запрос, было:
Key Lookup
263,153 (78%)
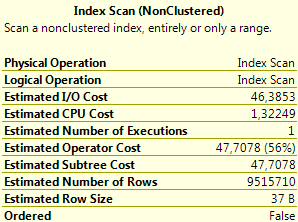
Стало:
Index Scan
47,7078 (56%)
Суммарная стоимость второго запроса была 336,006 стала 84,8048
Среднее логическое чтение при выполнении запроса уменьшилось на два порядка.
Информация передана разработчикам для изучения возможностей дальнейшей оптимизации.
То есть, при сохранении логики покрывающий индекс снижает стоимость запроса в 2-4 раза.
Но это отчасти полумера, столь дорогие запросы желательно переписать, оптимизировать.